ウェブ上には膨大な量の情報が存在しています. ウェブから情報を抽出・組織化して知識情報を取り出そうという研究領域はウェブマイニング(Web mining)と呼ばれます.
現在,以下のような研究活動を行っています.
データベースを用いたウェブからの情報抽出
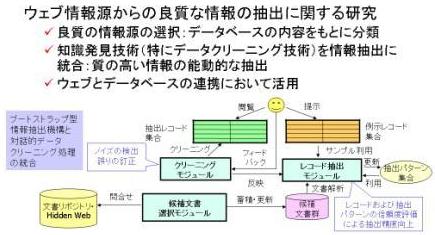
データベースシステムに蓄えられた情報とウェブ上に存在する多様な情報を連携して有効活用を図ろうというのが本研究の目的です. 特に,データベースの内容に関連が深いウェブ上の情報源を探索し,そこから情報を抽出してデータベースと統合するという点に着目し,以下の課題について特に検討しています.
情報源の選択手法:膨大な数のウェブ情報源から,統合の対象として適切な情報源を選択する. 統合対象のデータベースの情報を用いて,情報源の分類・取捨選択を行う. データクリーニング手法との連携:ノイズを含んだ情報から誤りを検出したり情報の修正を行う処理のことをデータクリーニングと呼びます. データクリーニングは,データマイニングの前段階などとしても大いに着目されている領域です. 本研究では,データクリーニングの手法をウェブからの情報抽出に連携することで,質の高い情報抽出を目指します.
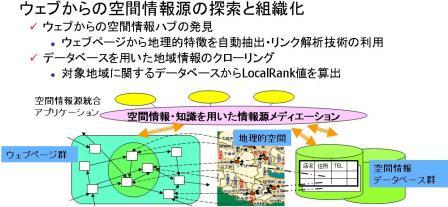
ウェブ上の空間情報源の探索と統合
この研究では,ウェブ上に存在する空間情報(特定の値域に関する情報を有するサイト・ページなど)を地域性を考慮してランク付けする方式や,特定の地域に対する有用な情報を有する空間情報源を抽出する方式の開発を進めています. また,ユーザが提供するデータベースをもとに,トピックにフォーカスしたクローリングを行い,有用な情報を抽出するための手法についても研究を行っています.