人間の日々の活動で,電子化された膨大な量のテキストデータが生み出されています. 本研究では,大量のテキストデータに存在する有用な情報を有効に活用するためのテキストマイニングの開発を目指しています. 情報検索やデータマイニングの技術の活用を図ります.
以下は現在のプロジェクトです.
新規性に着目した時系列文書のインクリメンタルなクラスタリング
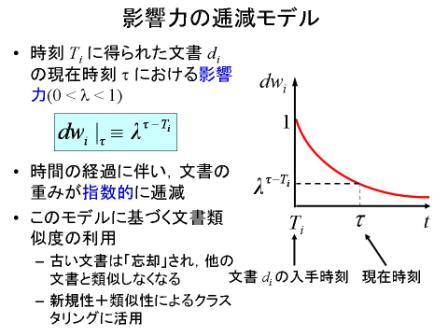
ネットワーク上で時々刻々と配信されるオンラインのニュース,RSS,ブログなどは,出版された時刻などの情報が伴いますが,このような文書を本研究では時系列文書と呼んでいます. 時系列文書は,一般に新しいものほど価値が高く,古くなればなるほど価値が落ちていくという性質を有しています.
大量の文書を要約してグループ化するための技術として,従来よりクラスタリング(clustering)の研究がなされてきましたが,これまでの研究では新規性を考慮してクラスタリングを行うアプローチはありませんでした. そこで本研究では,新規性の高いデータをより重視し,古くなったデータを忘却していくような文書類似度のモデルを提案し,次々と配信されてくる時系列文書を効率的にクラスタリングするためのインクリメンタルな文書クラスタリング手法を開発しています.
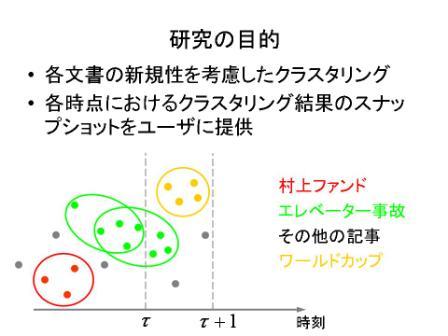
新規性を重視する(逆にいえば古い文書を忘れていく)という考え方を指数的な忘却としてモデル化し,それを用いて文書の類似度を導出し,クラスタリングで利用しています.